The first wave of AI servers is aging out in 18 to 36 months, and the hardware leaving the rack is worth more than most disposition programs assume. Here is how to recover the capital before the window closes.
For most of the last two decades, decommissioning a data center was a slow, infrequent event. Hardware ran for five to seven years, got wiped, and left the building on a pallet. Planning around it could wait until the lease was nearly up.

That clock has broken. AI infrastructure has compressed the hardware lifecycle to a fraction of what it was, and the equipment cycling out is worth far more than the gear it replaced. The first large wave of AI servers is reaching end of primary life right now, and the way an organization handles that retirement is increasingly the difference between recovering serious capital and writing it off. Decommissioning is no longer a cleanup task at the end of a refresh. It is a recurring financial event that deserves the same discipline as any capital decision.
| Metric | Detail |
|---|---|
| 18–36 months | AI server life, vs. 5 to 7 years traditionally |
| $15,000–$20,000 | Per-unit NVIDIA H100 secondary-market range |
| Up to 40% | Value lost if not remarketed within roughly 60 days |
| $19.94 billion | Projected decommissioning market size by 2032, up from $12.95 billion in 2026 |
The first GPU retirement wave has already started
The servers built for the generative AI boom of 2022 through 2024 are not failing. They are simply being outrun. Each new GPU generation delivers a step change in performance and efficiency, which makes the previous one expensive to keep running at scale. The result is a refresh cadence that would have looked reckless a few years ago: AI GPU servers are now cycling out within roughly 18 to 36 months of deployment, against the traditional five to seven year horizon for enterprise hardware.
Hardware lifecycle compression
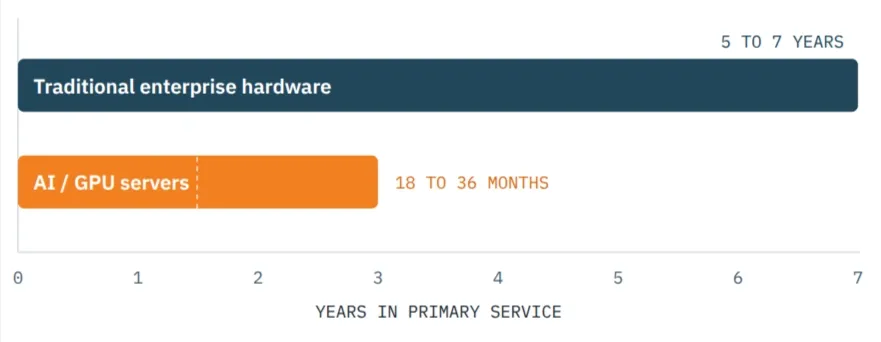
anges are illustrative of industry norms. The compressed cadence puts the first major AI retirement wave in the 2026 to 2029 window.
And it is worth being precise about why this hardware is leaving. It is rarely obsolete in any functional sense. It is being pushed out by physics and economics. Rack power density has climbed from the familiar 5 to 15 kW range to anywhere from 50 to 140 kW for dense GPU systems. Making room for that often means facility level electrical and cooling upgrades, which in turn force perfectly functional adjacent networking and storage gear out earlier than anyone planned.
The market reflects the scale of it. Research and Markets put the global data center decommissioning services market at $12.95 billion in 2026, with projections reaching $19.94 billion by 2032 at a compound annual growth rate of 7.37 percent. That growth is not organic drift. It is a structural shift in how quickly hardware is deployed, aged, and retired.
Retiring AI hardware is an asset, not e-waste
Here is the part that catches finance teams off guard. A GPU server retired after two or three years is nowhere near the end of its useful life to someone else. Mid-market firms, research institutions, and buyers who cannot get fresh allocations from the manufacturer are actively competing for last-generation accelerators.
That demand shows up in real numbers. NVIDIA H100 GPUs have continued to trade in the $15,000 to $20,000 per unit range on the certified refurbishment market, depending on configuration and timing. Multiply that across a fleet and the recovery opportunity becomes a line item the CFO should care about.
Consider the total cost of ownership math on a single high-end GPU server purchased for roughly $300,000, amortized over four years.
| End-of-life treatment | Residual recovered | Effective annual cost | TCO vs. scrap |
|---|---|---|---|
| Treated as scrap | $0 | ~$115,000 | Baseline |
| 30% recovery at retirement | ~$90,000 | ~$92,500 | ~20% lower |
That is close to a 20 percent swing in TCO on one machine. Across a fleet of hundreds, it is the difference between funding a meaningful share of the next refresh and starting from zero.
There is also a structural insight worth building into the plan. Selling intact, refurbished GPU servers as complete turnkey units frequently nets more than stripping them for parts, because secondary buyers will pay a premium to skip the engineering complexity of reassembling delicate, liquid-cooled, high-bandwidth AI hardware. Disposition strategy is not just about whether to sell. It is about how.
The value window is short, and it is closing
The catch is that this value is perishable. Secondary market pricing for a given GPU generation compresses quickly the moment its successor ships in volume. As H200 and Blackwell systems define the new performance baseline, the resale value of an H100 fleet steps down with them.
Recoverable value over time: acting fast vs delaying
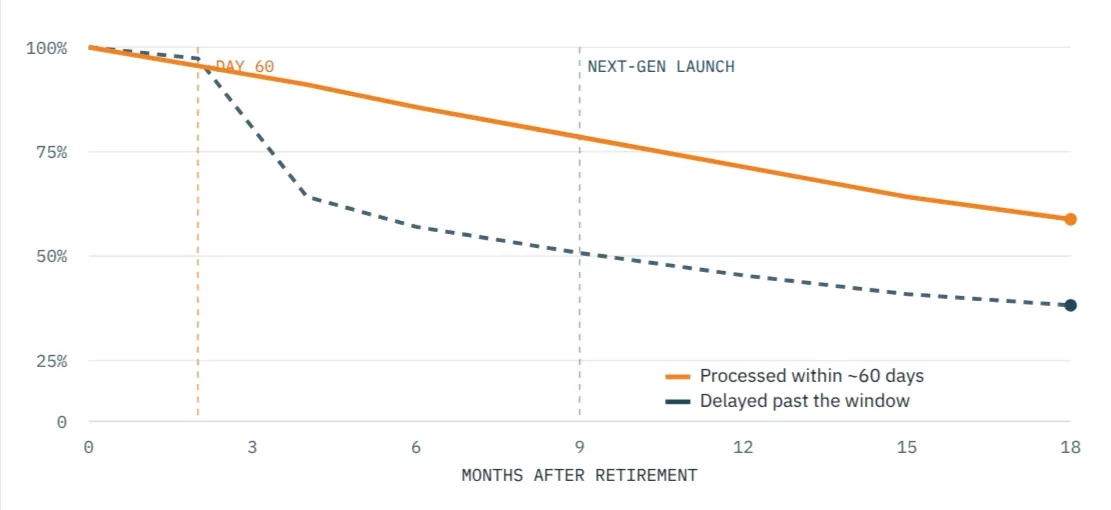
Timing compounds the effect. Gartner has noted that hardware not processed for the secondary market within roughly 60 days can lose up to 40 percent of its recoverable value. Stack that on top of generational price compression and the lesson is blunt: the recovery decision is made at the migration planning stage, not after the racks have already been pulled and stacked in a hallway.
This is the single most common and most expensive mistake. Organizations set a detailed migration timeline and treat disposition as an afterthought to schedule once the new gear is live. By then the window is already narrowing.
Two ways to recover value: outright sale versus consignment
How you sell matters as much as when. There are two broad models, and the right one depends on the assets and your tolerance for time versus certainty.
An outright buyout is the fast, simple path. A vendor assesses the fleet and pays a fixed sum upfront. You get certainty and immediate cash, and you hand off the work entirely. The tradeoff is margin. The buyer has to resell the hardware to make money, so their offer bakes in a discount against what the assets will eventually fetch.
A consignment model flips the economics. Rather than selling to the vendor, you consign the hardware to a partner who remarkets it on your behalf and returns the realized value minus an agreed commission. You capture a larger share of what the market actually pays.
| Dimension | Outright buyout | Consignment |
|---|---|---|
| Cash timing | Upfront, immediate | As assets sell through |
| Value captured | Lower, resale margin baked into the offer | Higher, market price minus commission |
| Who holds the risk | Vendor assumes all of it | Shared, partner remarkets for you |
| Speed to close | Fast | Depends on sell-through |
| Best fit | Commodity gear, speed-critical exits | High-residual, high-demand assets such as current-gen GPU and AI hardware |
This model makes the most sense precisely when residual values are high and demand is liquid, which is exactly the situation with current-generation GPU and AI hardware. The upside you give away in an outright buyout on a fleet of $15,000 accelerators is substantial.
Consignment also sidesteps a hidden drag on recovery value. Most disposition vendors sell through broker chains, where multiple intermediaries each take a cut and negotiate the price down before the asset ever reaches an end buyer. A partner with direct buyer relationships and active remarketing channels removes those stacked markdowns, which is where a meaningful portion of the difference between models comes from.
The honest tradeoff with consignment is time. Value is realized as the hardware sells rather than on day one, and because pricing decays, a good consignment program is built around moving assets fast through established channels rather than letting them sit. Matched correctly to the asset, it is the higher-yield option for hardware with strong secondary demand.
Why most ITAD contracts can no longer keep up
If your IT asset disposition contract was signed three to five years ago, it was scoped for a different world, and the gap is not limited to your AI racks. It runs across the entire estate.
Three things have shifted for every class of hardware. First, retirement volume has accelerated and converged. Cloud cost pressure, M&A activity, and AI demand are all pushing organizations to shrink physical footprints at the same time, putting more decommissioned hardware into the market than legacy programs were built to handle. Second, the data-bearing surface has expanded. Configuration data on flash-based firmware now requires sanitization even on devices that were never considered compute or storage, something older contracts simply do not address. Third, documentation standards have tightened. Per-serial-number chain of custody is now the baseline audit expectation, not a premium upgrade.
There is also a book-value trap that applies to any hardware, not just GPUs. An asset that is fully depreciated on your books can still carry real secondary-market value, and a recycle-first vendor has no incentive to tell you the difference. Disposition decisions made against an internal depreciation schedule consistently leave money on the table because that is not what the market actually pays.
AI hardware is simply the sharpest example of the gap. A five-year contract written before 2022 almost certainly lacks GPU-specific sanitization procedures, handling protocols for HBM3 stacked memory, or the per-device documentation that compliance teams now demand. It is the most extreme version of a shortfall that exists, to some degree, for your standard servers, storage arrays, and networking gear too.
It is also worth separating two services that vendor marketing tends to blur. Generic ITAD, the depot-style processing of end-of-life devices, is not the same operation as decommissioning a live data center. Pulling a populated row out of an active facility without taking down adjacent production is a field operation that only a small subset of providers can execute reliably, and it applies to any dense estate, not only GPU fabric. The broader ITAD market is expected to roughly double, from $18.6 billion in 2026 to $40.1 billion by 2035.
The compliance layer enterprises underestimate
Recovery is only half the story. The other half is proving, to an auditor's satisfaction, that every retired device was handled correctly. Modern AI hardware raises the bar on data destruction in ways standard wiping does not cover.
| Component | Software overwrite sufficient? | Required approach |
|---|---|---|
| Standard HDD | Yes | Overwrite or degauss (NIST Clear / Purge) |
| Standard SSD / NVMe | Partial | Crypto-erase with verification (NIST Purge) |
| Over-provisioned high-density NVMe | No | NIST SP 800-88 Rev. 2 Destroy-level |
| GPU HBM3 stacked memory | No | NIST SP 800-88 Rev. 2 Destroy-level |
| Flash-based firmware (config data) | No | Device-specific sanitization procedure |
HBM3 stacked memory in GPU accelerators and the over-provisioned cells in high-density NVMe storage cannot be fully reached by a software overwrite. Reaching them requires NIST SP 800-88 Rev. 2 Destroy-level sanitization, not a factory reset.
For regulated organizations, the documentation is not optional. Per-serial-number chain of custody is what satisfies SOX Section 404, HIPAA, and FISMA requirements. Batch-level certificates that say "X devices processed in Q4" do not. The evidentiary gap that produces audit findings is rarely a failure to sanitize. It is the inability to prove which specific devices were processed, by which method, on which date.
This is where certification stops being a checkbox. R2v3 certified remarketing combined with serialized, device-level documentation is what lets an organization recover asset value and pass an audit from the same engagement, rather than choosing between the two.
Building a recovery-first decommissioning plan
The organizations that recover the most value share a common habit: they treat disposition as part of the project from day one, not as cleanup afterward.
A recovery-first decommissioning workflow

- Inventory at the component level before anything moves. Capture make, model, age, and condition for every asset. Servers, storage, GPUs, networking, and memory all carry different residual values, and you cannot price what you have not catalogued.
- Set the disposition timeline the same day you set the migration timeline. Every cutover date and facility exit has a hardware implication. Mapping them early gives a partner enough lead time to assess and move assets before the value window closes.
- Choose the recovery model per asset. Match outright sale, consignment, redeployment, refurbishment, recycling, or destruction to each class of hardware based on its secondary-market demand and your data sensitivity requirements.
- Pre-qualify one partner who can do both. A provider that decommissions and remarkets under a single chain of custody, with R2v3 and the relevant data-destruction certifications, eliminates the handoffs where compliance gaps and value leakage both happen.
| Asset class | Typical residual | Recommended path |
|---|---|---|
| Current-gen GPU / AI servers | High | Consign or sell intact, move fast |
| Prior-gen servers / CPU compute | Moderate | Sell or redeploy |
| Storage arrays | Low to moderate | Sell or recycle after Destroy-level sanitization |
| Networking (switches, routers) | Moderate | Sell or redeploy |
| End-of-life or damaged | Minimal | R2v3 recycle with certificate of destruction |
The refresh is a source of capital, if you plan for it
The AI hardware cycle is usually framed as a cost problem: more power, more cooling, more frequent and expensive refreshes. That framing misses half the picture. Every retirement wave is also a recurring source of recoverable capital, and the organizations that build a plan around it turn what looks like a sunk cost into funding for the next generation.
Recover the capital before the window narrows

ReluTech handles data center decommissioning end to end, from secure rack pull through R2v3-certified asset recovery, with serialized chain-of-custody documentation built for audit. Our buy, sell, and consignment programs are designed to capture the secondary-market value of retiring hardware rather than discount it away, and the proceeds can be applied directly toward funding your next refresh or your AWS migration through our Migration IQ platform.
If you are scoping a refresh or a facility exit, the recovery window is open now.
